
1.AIと品質
「生成AI」がユーキャン新語・流行語大賞のトップテンに選ばれたのは2023年のことです。この年には「ChatGPT」もノミネートされ、広く注目を集めました(※1)。当時は「ChatGPTに質問すると変な答えが返ってくる」と面白がって使う人が多かった記憶があります。それから2年が経った現在では、生成AIの精度は飛躍的に向上し、「迷ったら生成AIに相談する」という人も増えています。ソフトウェア開発の現場でも例外ではなく、開発のさまざまな場面で生成AIが活用されるようになっています。
(1)QA4AIとAI4QA
AIと品質については、主に2つの視点があります。
1つ目は「AIが使われているソフトウェアの品質をどう保証するか」という視点です。これはQuality Assurance for AI、略して「QA4AI」と呼ばれます。AIを組み込んだソフトウェアでは、入力に対する出力(回答)を事前に予測することが難しく、期待結果を定義したり、出力結果の正当性を評価したりすることが困難です。こうした課題に対応するため、以下の2つのガイドラインが公開されています。
2つ目は、「AIを活用してソフトウェアの品質保証を支援する」という視点です。これは「AI4QA」(品質保証のためのAI)と呼ばれることがあります(※4)。近年では、テストや開発支援ツールにAIが組み込まれ、作業効率の向上とともに品質保証の役割も担うようになっています(※5)。AIが支援する範囲やその効果はさまざまですが、ソフトウェア開発にAIを活用することは、もはや特別なことではなくなっています。
(2)生成AIによる開発と品質保証
今回は、2つ目の視点(AI4QA)に関連して、「生成AIを使ってソフトウェアを開発した場合の品質保証」についてご紹介します(図1)。
生成AIを活用することで、開発効率や品質の向上が期待される一方で、「生成AIは誤った情報を出力することがある」というリスクも存在します。そのため、生成AIによって作成されたソフトウェアの品質が十分かどうかを確認・検証することが重要です。
具体的には、設計・コーディング・レビュー・テストなど、これまで人間が担っていた開発作業を生成AIが行った場合、その成果物や作業プロセスの品質をどのように保証するかを考える必要があります。
例えば、
- レビューやテストはどの程度実施すればよいのか
- 従来の品質評価指標(例:バグ検出密度)はそのまま使えるのか
といった課題に向き合わなければ、生成AI時代のソフトウェア開発における品質保証は成り立ちません。これらの課題をクリアすることで、ユーザーや顧客が安心してソフトウェアを利用できる環境が整っていきます。
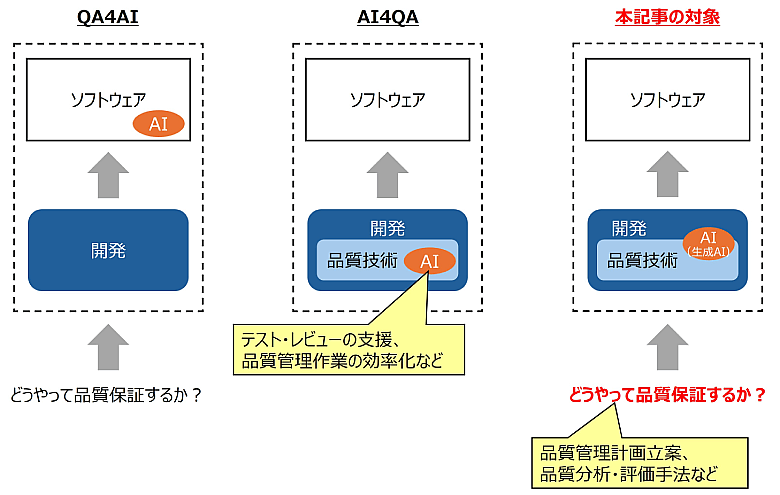
図1:AIと品質の関わり方と本記事の対象
https://www.nttdata.com/jp/ja/trends/data-insight/2024/0315/
2.技術的な背景(基礎知識)
(1)生成AI(モデル、進化、開発への適用)
生成AIのモデル
生成AIの基盤には「モデル」と呼ばれる仕組みがあります。中でも注目されているのが大規模言語モデル(LLM)です。これは膨大な文章データを学習し、次に続く単語や文章を予測することで、自然な文章を生成します。ChatGPTのように会話ができるモデルや、文章からイラストを生成するモデルも存在します。これらのモデルは人間の脳を模した「ニューラルネットワーク」という仕組みに基づいており、柔軟な応答や創造的なアウトプットを可能にしています。
生成AIの進化
生成AIはここ数年で急速に進化しました。初期のAIは単純な応答しかできませんでしたが、学習データの増加と処理能力の向上により、自然な文章や高品質な画像を生成できるようになっています。さらに「事前学習モデル」という手法の登場によって、一度学習した知識をさまざまな分野で活用することもできます。この技術を活用することで、翻訳、要約、プログラム作成など、多様なタスクに対応できる汎用性が実現し、社会での活用範囲が一気に広がっています。
ソフトウェア開発への適用
生成AIはソフトウェア開発の現場でも大きな役割を果たしています(※6)。ソースコードの自動生成やバグ修正の提案、要件定義や設計書の作成補助など、開発者の作業効率を高めています。さらに、システム運用に関する問い合わせ対応や、障害発生時の初動対応を担うチャットボットなど、ソフトウェア開発以外の分野でも生成AIの活用が広がっています。このように、開発から運用に至るまで、全体的な生産性向上に寄与しています(図2)。
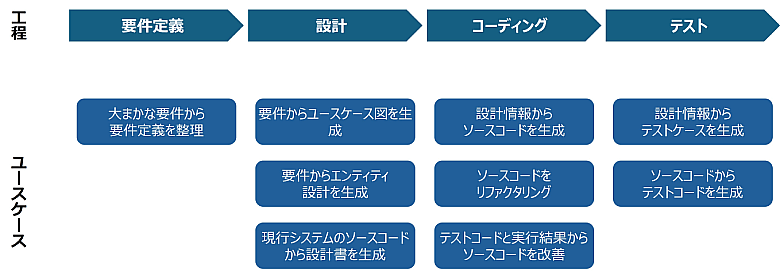
図2:ソフトウェア開発で生成AIを活用するユースケースの例
(2)プロンプト(プロンプトエンジニアリング)
プロンプトとは生成AIに与える質問や指示文のことです。生成AIは入力された文章を基に回答を生成するため、指示の仕方によって結果の質が大きく変わります。例えば、「旅行プランを教えて」と曖昧に入力すると広すぎる答えが返ってくる可能性があります。しかし、「東京発・家族4人・2泊3日・子どもが楽しめる旅行プラン」と条件を加えることで、より具体的で実用的な提案が得られます。このように、狙った答えを引き出すための工夫を「プロンプトエンジニアリング」と呼び、生成AIを効果的に活用するための重要なスキルとなっています。
(3)ハルシネーション
生成AIは便利なツールですが、時に「もっともらしいが事実ではない答え」を返すことがあります。これを「ハルシネーション」と呼びます。原因は、生成AIが真実かどうかを判断するのではなく、学習データを基に次に続く文章を予測しているためです。例えば、存在しない書籍を「参考文献」として提示したり、歴史にない出来事を事実のように語ったりする場合があります。こうした回答は初心者には見分けがつきにくいため、利用者自身が内容を確認する姿勢が欠かせません。生成AIは万能ではなく、あくまで補助的なツールであるという理解が重要です。
https://www.nttdata.com/jp/ja/trends/data-insight/2025/0124/
3.生成AIを使ったソフトウェア開発における品質保証の難しさ
ここでは生成AIによるソースコードの自動生成を例に、生成AIを使った開発における品質保証の難しさについて解説します。
(1)出力結果の正確性や一貫性に問題がある
生成AIが作るソースコードは、見た目には正しく見えても、実際に動かすと失敗することがあります。これは、学習データが古かったり偏っていたりすることで、廃止されたAPI(機能を呼び出す仕組み)や存在しないライブラリ(外部部品)を使用してしまうケースがあるためです。例えば、「最新バージョンのJavaでコーディングして」と指示しても、学習データが古い場合には旧バージョンのソースコードが生成されることがあります。
また、生成AIのモデルがバージョンアップされた場合や、参照する情報源の違い、直前のやりとりの影響などによって、同じ質問でも日によって異なる回答が返ってくることがあります。
(2)ブラックボックスである
生成AIは「なぜそのソースコードを出力したのか」が分かりにくい仕組みになっています。どのような情報を学習しているのか、どのような考え方で実装を選んだのかを説明できないことが多く、原因の特定や説明が難しくなります。例えば、本当はシンプルなfor文で書ける処理にもかかわらず、複雑な再帰処理を使ったソースコードが生成されることがあります。また、開発者が意図していないグローバル変数を勝手に使用する場合もありますが、その理由を追跡することは困難です。
基本的に生成AIの内部ロジックは公開されておらず、「どのようなデータで学習したのか」「内部でどう判断しているのか」が見えない、いわゆる「ブラックボックス(中身が隠されている状態)」です。そのため、バグが見つかったときに「プロンプト(指示の仕方)が悪かったのか」「生成AIの中身が変わったのか」「外部から取得した情報が変わったのか」といった原因の切り分けが難しくなります。さらに、ログを確認しても「どの資料を参考にしたのか」「どのルールを重視したのか」が分からない場合があり、ソースコードレビューにおいても「どこを修正すべきか」の根拠が曖昧になることがあります。
(3)従来の定量的な品質評価指標だけでは評価し辛い
バグを十分に見つけたかどうかを評価する際の指標として、一定量のソースコード(例:1,000行)に対して検出されたバグの数を示す「バグ検出密度」が用いられてきました。しかし、生成AIを使った開発では、この指標だけでは品質を十分に評価することが難しくなります。理由は以下のとおりです。
- コーディング内容にバラつきがある:生成AIが生成するソースコードは、同じ機能でもタイミングによって内容が異なります。見た目や書き方が違っても動作することはありますが、可読性や保守性が低い、例外処理が不十分といった問題が潜んでいる場合があります。
- ソースコードの量が安定しない:生成AIは出力するソースコードの量や構造が毎回異なるため、ソースコードの量に依存する指標の場合、類似プロジェクト等の統計から求めた指標値との比較がしにくくなります。
- バグの量が予測できない:生成AIがどのような誤りをどの程度含むかを事前に予測するのは難しく、従来の統計的なバグ予測指標が使えないだけでなく、生成AIを活用した開発に対応した指標値を設定するのも容易ではありません。
このような理由から、生成AIが作ったソースコードが十分な品質を保っているかどうかは、バグ検出密度だけでは判断し辛く、保守性、例外処理の妥当性、コーディング規約の順守など、複数の観点を組み合わせて評価する必要があります。
4.生成AIを使ったソフトウェア開発における品質保証の基本的な考え方
ソフトウェア開発の品質保証の基本的な考え方は、「開発プロセスが適切に管理され、最終的な製品が要求された仕様通りに機能することを保証する」です。この点は、生成AIを使ったソフトウェア開発であっても変わりません。生成AIは「有能な新メンバー」として、要件定義、設計レビュー、テストなどのプロセスに計画的に組み込みます。プロンプトと生成結果の記録、修正履歴の管理、責任の所在の明確化を徹底し、重要かつ高リスクな箇所ほど人間によるレビューを厚くします。生成AIを成果物の作成やレビューを自動化するための道具として活用しつつ、最終判断は人間が行う。この線引きが安定したソフトウェア品質につながります。
(1)人間が開発した時と品質保証の基本は変わらない
生成AIが出力する成果物は、完成品ではなく「たたき台」です。当社で生成AIを使った開発や検証を行った結果では、成果物の正解率(期待する結果との一致度)はばらつきがあるものの、おおよそ60%程度でした。ハルシネーションを含む誤りや思い込み、抜け漏れが起こり得るため、要件の確認、ソースコードレビュー、例外処理の確認・補足、セキュリティ点検などは人間が責任を持って行います。可読性や保守性、ログや監視の仕込み、ライセンス確認も従来どおりの基準でチェックします。テストは単体・結合・受入など各工程で実施し、生成AIが出力したテストコードも鵜呑みにせず、境界値やエラー系のテストケースを人間の視点で確認・補強します。「品質保証の基本は変わらない」を合言葉に、生成AIを安全に活用することが重要です。
(2)事前の検証を基に品質保証方針を策定する
まずは小規模な範囲でプロトタイプ検証を行い、どこまでを生成AIに任せられるかを明確にします。その際、適用範囲だけでなく、生成AIの活用に伴うリスクを抽出し、具体的な対策を立案することが重要です(例:根幹となる業務ロジックは人間が担当し、周辺機能や補助的な設計検討を生成AIに任せるなど)。
次に、検証を通じて得られた特徴や課題を整理し、設計やテストにおける観点を作成します。同時に、品質評価の方法や基準を定めることで、開発プロセス全体における品質保証の方針を整理します。さらに、プロンプトを標準化し、目的・前提条件・制約・出力形式などをテンプレート化します。これらを組み合わせることで、生成AI活用に伴う不確実性を低減し、成果物の品質のばらつきや手戻りを最小化することが可能となります。
(3)データを蓄積・分析して品質保証方針を改善する
生成AIを活用した開発を行いながら、プロンプト、生成結果、レビュー指摘、修正時間、テスト通過率などを継続的に記録します。さらに、生成AIとのやり取りの回数や履歴、生成AIに起因するバグの傾向(例:例外処理の誤り、境界値の漏れ、命名規約違反)を確認し、より品質の高い成果物を生成するためのポイントを定量的・定性的な観点から絞り込みます。プロジェクト内で定期的に振り返りを行い、開発標準やコーディング規約、プロンプトテンプレートなどを更新し、良い事例をナレッジとして共有します。生成AI開発で得られた各種データを蓄積し、小さな改善を繰り返すPDCAを行うことで、「適切なプロセスと指標」を育てることが、生成AI時代の品質を安定させるポイントになります。
なお、生成AIを活用した開発では、ソースコード量をベースとしたバグ検出密度などの指標による品質保証が難しいのは前述のとおりですが、「観点カバレッジ」や「DDPモニタリング」など、密度に依存しない品質保証の手法を活用することが可能です(※7)。
https://www.nttdata.com/jp/ja/trends/data-insight/2021/0204/
5.今後の展望
生成AIを活用したソフトウェア開発では、最終的に人間による確認が不可欠であり、事前の検証やデータの蓄積といった作業も必要になります。そのため、作業効率や生産性の向上を目的に生成AIの導入を検討している方にとっては、「品質保証に関する作業が思ったほど削減されない」「むしろ負担が増えるのでは」と感じることもあるかもしれません。
しかし、品質保証に関わる作業もまた、生成AIなどの技術を活用することで効率化が可能です。まずは、品質保証をどのように捉えるかを整理し、必要な作業を明確にしたうえで、生成AIに任せられる領域を見極めていくことが重要です。
NTT DATAでは、すでに多くの開発プロジェクトにおいて生成AIの活用が進んでいます(※8)。大規模システムの開発においても、従来どおりの高品質を維持するために、生成AIを単なる効率化の手段として捉えるのではなく、生成AIが作成した成果物やその活用プロセスの品質を確実に担保することを重要視しています。
そのため、こうした品質確保の考え方を反映したガイドラインを策定し、開発プロセスにおける標準的な指針として位置づけています。さらに、このガイドラインを活用した社内教育の実施や、一部の品質保証作業を生成AIで代替する取り組みも進めています。
2025年現在、生成AIと人間は互いに補完し合う関係にあり、品質保証においても人間の介入が大きな役割を果たしています。しかし、生成AIの進化が続けば、将来的には人間が確認すべき範囲が徐々に縮小されていく可能性があります。
すでにAIエージェントが自ら開発を行い、品質保証まで担う技術も登場しつつあり、近い将来には「生成AIだけで開発から品質保証まで完結するソフトウェア」が実現するかもしれません(※9)。
このような技術の進化に伴い、人間とAIの関係性にも大きな転換点が訪れると考えられます。ソフトウェア開発技術の進化に合わせて、品質保証の考え方や技術も柔軟にアップデートしていくことが求められます。
https://www.nttdata.com/jp/ja/trends/data-insight/2025/0910/

NTTデータが本腰「生成AIありきのSI」についてはこちら:
https://xtech.nikkei.com/atcl/nxt/column/18/02905/
AIとソフトウェア品質技術についてはこちら:
https://www.veriserve.co.jp/asset/approach/column/ai/advanced-tech-ai04.html
あわせて読みたい: