
1.はじめに
近年の大規模言語モデル(LLM)の進化により、生成AIを用いた業務効率化やナレッジ活用が急速に広がっています。OpenAIの「ChatGPT」、Anthropicの「Claude」、Googleの「Gemini」など、クラウドベースのLLMは自然言語処理の水準を大きく引き上げ、プロンプトベースでのタスク実行、マルチモーダル処理、エージェント的な活用まで多様なユースケースが現実のものとなっています。
しかし一方で、クラウド型LLMの業務適用には、情報流出リスク、ネットワーク遅延、従量課金によるコスト不確実性など、無視できない課題も存在します。とりわけ、ミッションクリティカルなシステムや閉域環境においては、これらの制約がクラウド型LLM導入の大きな障壁となります。
このような制約環境において、ローカルで動作可能な生成AIモデル(ローカルLLM)は、より制御可能かつカスタマイズ性の高い選択肢として注目を集めています。セキュリティや応答性の要件を満たしつつ、業務特化型のチューニングや業務ナレッジとのRAG統合など、より業務にフィットした構成が可能です。
本記事では、クラウド型LLMの課題を補完する選択肢として、「ローカルLLM」に注目し、その特徴や選定ポイント、モデルのカスタマイズ手法について技術的な観点から解説します。
2.なぜローカルLLMなのか
クラウド型LLMは非常に高い性能を持つ一方で、業務要件によっては導入のハードルとなるケースも少なくありません。そのためオンプレミス環境や閉域網で生成AIを活用したいというニーズは、近年ますます高まっています。以下では、クラウド型LLMと比較した場合のローカルLLMの強みを4つの観点で整理します。
セキュリティ・ガバナンス上の要請に応えられる(顧客データ、機密情報)
企業システムでは、個人情報や機密データの取り扱いが避けられない場面も多く、外部クラウドにデータを送信できないケースがあります。金融、医療、防衛、製造などの業種では特にその傾向が強く、厳格なセキュリティポリシーや監査要件を満たす必要があります。ローカルLLMは、プライベートAIとして活用することで入力・出力をすべて社内で完結できるため、こうしたニーズに非常に適しています。
SaaS型大規模モデルの制約とコストの課題を解決する
クラウドLLMの多くは従量課金型APIとして提供されており、長期的・大規模な利用ではコストの見通しが立ちにくいのが実情です。また、プロンプト設計やトークン数制限、レスポンス内容のブラックボックス性など、開発現場で扱いにくい傾向もあります。ローカルLLMはこの点で、コスト予測と挙動制御のしやすさが強みです。
カスタマイズ性・制御性が高い
ローカルLLMは、ファインチューニングや継続事前学習を行ってモデル自体をチューニングしたり、社内ドキュメントをプロンプトに入れ込むRAG(Retrieval-Augmented Generation)構成を採用したりすることにより、業務特化の高度なカスタマイズが可能です。また、前処理・後処理の実装や、モデル応答のロジック調整をシステム側で自由に行えるため、業務ごとの要件やユースケースに応じた最適な生成AI機能を設計できます。
オンプレミス/エッジ導入の文脈での優位性を持つ
現場作業やネットワーク接続が制限される環境(例:工場内端末、保守点検デバイスなど)では、クラウドへの常時接続が前提となるモデルは利用が難しいことがあります。ローカルLLMは、エッジデバイスやオンプレミス環境でも動作可能な軽量構成を採ることも可能なため、リアルタイム性や可用性といった要求にも対応可能です。
3.ローカルLLMの例
ローカルで利用可能な生成AIモデルは、多種多様な選択肢が存在します。GoogleのGemma 3やMetaのLlama 4など海外製モデルだけでなく、NTTのtsuzumiやPreferred NetworksグループのPLaMo 2.0 Primeなど、国産のモデルも存在します。日々新たなモデルが出ているため、活用可能性については常に評価を行っていく必要があります。
4.モデル選定
顧客業務へのローカルLLMを用いた生成AIソリューション適用を考える際には、単に性能だけでなく、用途、制約、拡張性など複合的な観点からの評価が不可欠です。ここでは、ローカルLLMの選定・導入を検討する際に、NTT DATAが特に重要と考えるポイントを紹介いたします。
業務要件との適合性
モデル選定の第一歩は、対象業務において「どのような処理を求めているか」を明確にすることです。とくにローカルLLMを業務へ適用する際には、タスクごとの適合性を意識する必要があります。以下にいくつかの業務要件例を挙げます。
- RAGによる社内QA・ナレッジ検索:ユーザーの質問に対して、社内文書やFAQデータを参照しながら回答を生成する場合、モデルには文脈の保持、簡潔な回答生成、補足情報を混ぜない厳密性が求められます。
- 要約:議事録やレポート、技術文書を要約する際には、入力文の長さに対応できるトークン長と、要点抽出の精度が求められます。また、日本語での要約を行う際には、日本語特有のハイコンテキストな表現を理解して要約できるかが重要になります。
- 翻訳:翻訳では、単なる文法的変換にとどまらず、語調の自然さや業務用語への適応力が求められます。ビジネスにおいては文語体の翻訳能力も重視されるため、過度に口語での会話に最適化されたモデルは適さない場合があります。また、業界特有・企業特有の表現に対応できるかは未知数です。さらに、十分な指示追従能力を持たないモデルは、入力された言語をそのまま返してしまう場合があるため、注意が必要です。
- エージェント的活用:ユーザー指示を段階的なタスクに分解し、分解されたタスクを外部とやり取りしながら実行するには、Chain-of-ThoughtやTool Calling的な出力設計が可能なモデルが適しています。どのようなエージェントを組みたいかに応じて、複数のモデルを組み合わせることも検討の必要があります。
モデルサイズと精度のバランス
業務システムに組み込む際は、モデルの性能だけでなくリソース要件も考慮する必要があります。一般的に、パラメータ数が大きいモデルほど高精度ですが、推論環境においては高性能GPUを多量に使用するため、サーバ導入コストなどに課題が生じます。対象業務における精度とモデルサイズのバランスを考えて決定することが重要です。
商用利用可否・ライセンス
ユーザ数の制限や利用用途の指定など、商用利用に制限があるケースがあります。ライセンス内容は都度確認し、顧客環境に組み込む場合は再配布・再利用条件にも留意する必要があります。特に再販やSaaS提供を想定する場合、モデルライセンスとの整合性が重要です。
5.モデルカスタマイズ
ローカルLLMを業務で実用化するうえでは、既存の汎用(はんよう)モデルをそのまま使うだけでなく、目的に応じて適切にカスタマイズすることが重要です。ここでは、外部知識を動的に取り込むRAG構成と、モデル自体を調整するファインチューニング手法という2つの主な方向性について解説します。
外部知識を動的に取り込むRAG
RAGは、モデルに学習させるのではなく、外部のナレッジソース(社内文書、製品情報、FAQなど)を検索し、その情報をもとに応答を生成する仕組みです。
頻繁に更新される業務知識や、部署横断的なナレッジ共有など、静的なチューニングでは追従が難しい場面に適しています。また、回答の根拠情報(引用元)を提示できる点も、業務利用における信頼性を確保するうえで有効です。
モデル自体を調整するファインチューニング:教師ありLoRAや継続事前学習
LoRA(Low-Rank Adaptation)は、モデル全体を更新せずに一部のパラメータだけを効率的に調整できる軽量なファインチューニング手法です。比較的少量の教師ありデータ(例:質問と回答のペア、要約データなど)を用いて学習でき、FAQ要約、定型文の生成、非構造データからの情報抽出・構造化といった用途に適しています。また、業務ごとにアダプタ(LoRAレイヤー)を分けて構築すれば、同じベースモデルに対して複数業務への切り替え運用も可能です。
一方で、継続事前学習はより大規模な適応手法です。既存モデルの事前学習を、業務ドメインの大量のテキストデータ(例:業務マニュアル、業界記事、報告書等)で継続的に行うため、LoRAでは吸収しづらい言語的傾向や構文特性の反映、長文の一貫性向上などに効果的です。
カスタマイズ手法の選定にあたっては、それぞれの特性を理解し、業務要件に最も適した方法を選ぶことが重要です。以下の表では、どういった場合にどのカスタマイズ手法を適用するかを例示します。
| 対象 | カスタマイズ手法 | 例 |
| 業務知識の更新頻度が高く、柔軟な参照が求められる場合 | RAG | ナレッジベース活用 |
| 業務における入出力が明確である場合 | 教師ありLoRA | ルールに従った翻訳・要約や、帳票の構造化といった定型的なタスク |
| 業界固有の文体や専門用語が多く使われる場合 | 継続事前学習 | 医療や製造、法務などの業界固有の業務 |
これらの手法は互いに排他的なものではなく、業務の特性や導入段階に応じて、段階的に、あるいは組み合わせて活用することが可能です。たとえば、業界特化の継続事前学習を施したモデルにRAG構成を組み合わせると、言語理解の深さと最新ナレッジの柔軟な取り込みを両立することができます。
6.NTT DATAが提供する価値
NTT DATAでは、ローカル生成AIモデルの活用に向けて、モデル選定にとどまらず、「モデル調査・技術検証・業務適合性の評価」から「実業務向けのカスタマイズ」「導入支援」まで一貫した価値提供を行っています。
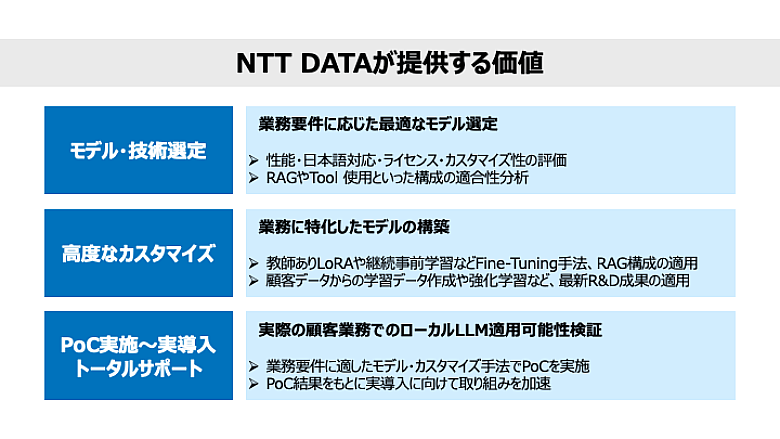
図:NTT DATAが提供する価値
7.まとめ
ローカルLLMは、セキュリティや応答性、カスタマイズ性が求められる業務において、クラウド型モデルを補完・代替する実用的な選択肢となりつつあります。NTT DATAでは、モデル選定からカスタマイズ、PoC実施~実導入までを一気通貫で支援できる体制と知見を有し、業種やユースケースに応じた最適な構成をご提案可能です。
ローカルLLMを活用した業務改革やPoCをご検討中の方は、ぜひNTT DATAまでご相談ください。

NTT DATAの生成AI(Generative AI)に関する取り組みについてはこちら:
https://www.nttdata.com/jp/ja/services/generative-ai/
tsuzumiについてはこちら:
https://www.nttdata.com/jp/ja/lineup/tsuzumi/
あわせて読みたい: