
Key Considerations for Implementing RAG in Generative AI
Building RAG systems that give enterprises control over generative AI
Companies are starting with back-office tasks such as report writing and policy searches, where they can apply generative AI with fewer risks. Retrieval-Augmented Generation (RAG) gives large language models access to internal data, improving accuracy and relevance. Teams achieve better results when they structure data carefully, assign departmental ownership, and validate outputs with domain experts. NTT DATA equips organizations to democratize RAG through no-code tools, training, and governance. It also offers DataRobot and is launching "Smart AI Agent™" services to automate workflows.
At the same time, these organizations face new challenges in deciding how to begin and where generative AI can add the most value. Back-office processes are one of the most promising entry points, as generative AI can be applied here with relative ease. To make effective use of company-specific knowledge in these areas, one mechanism is essential: Retrieval-Augmented Generation (RAG).
This article outlines the key considerations for building RAG and promoting its adoption across the organization.
1. Practical Applications of Generative AI
Since the launch of large language models (LLMs) like ChatGPT, generative AI has developed quickly. Its strength lies in handling natural conversation and supporting a wide range of tasks, which has accelerated efforts to use it across many business areas.
Gartner® divides potential applications into four categories. Ambitious initiatives are sorted into the "Game-Changing" category: including those aimed at creating new value in products and services or reshaping core business functions - and this is an area of rapid development. However, the most practical entry point is the "Everyday" category. This covers routine use cases such as generating and summarizing call center responses, drafting proposals and diagrams, searching internal policies, and preparing meeting minutes and reports.
Among these use cases, back-office tasks such as report writing and policy searches are especially well suited to generative AI for several reasons:
- Many of the tasks are standardized and supported by large volumes of existing data.
- Stakeholders are internal, making it easier to reach consensus and adjust processes.
- The risk of harm from incorrect AI responses is relatively low.
- These tasks usually do not involve sensitive or personal information.
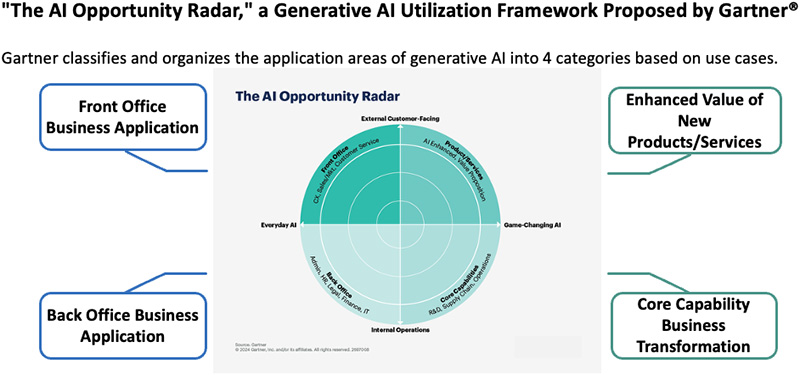
Figure 1
Gartner®, Get AI Ready - What IT Leaders Need to Know and Do, https://www.gartner.com/en/information-technology/topics/ai-readiness
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally, and is used herein with permission. All rights reserved.
2. What is RAG? How to Build It
RAG, or Retrieval-Augmented Generation, is a method that enables large language models (LLMs) to generate responses based on internal company data - such as policies, manuals, and regulations - by retrieving relevant information from a document store. This allows LLMs to handle queries beyond their original training data and reduces hallucinations by grounding responses in verified content.
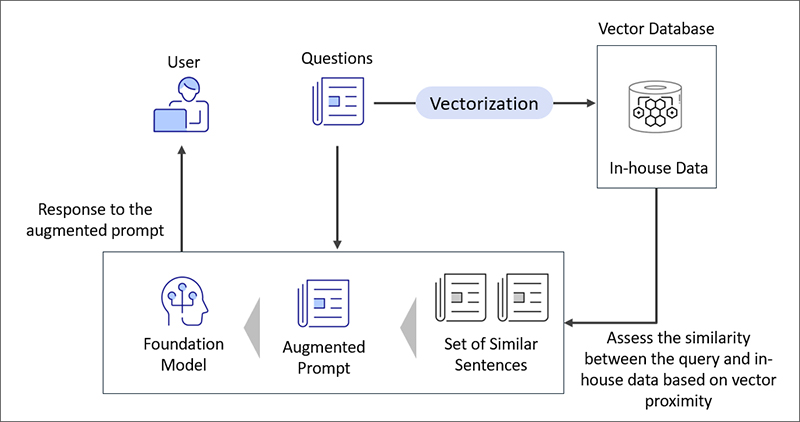
Figure 2: How RAG Works
When building RAG into a generative AI system, the scope and granularity of the data are critical. In NTT DATA projects, rather than relying on a single datastore with more than 100,000 rows, our approach of splitting information into 5-8 business domains and limiting each to 1,000 to 10,000 rows has produced far more accurate results.
Because terminology and context differ across departments, and the same term can mean different things depending on the role, developing RAG systems at the departmental level delivers better outcomes than a single, company-wide system.
To take this approach, organizations must be able to build, operate, and continuously improve multiple RAG systems. That raises questions about responsibility: who should own the process, and how should roles be shared between business units and digital transformation (DX)/IT teams?
Human validation is also essential to improving responses. This requires domain experts who understand the content. Enhancing search accuracy often depends on adding metadata to source documents, which also demands specialist knowledge. And since documents are updated daily, asking IT departments alone to maintain vector databases (VDBs) is not efficient.
We recommend giving each department the ability to build and manage its own RAG system (or systems). When departments generate ideas and implement use cases themselves, that leads to more agile and self-sustaining adoption of generative AI. We call this the "democratization of RAG development."
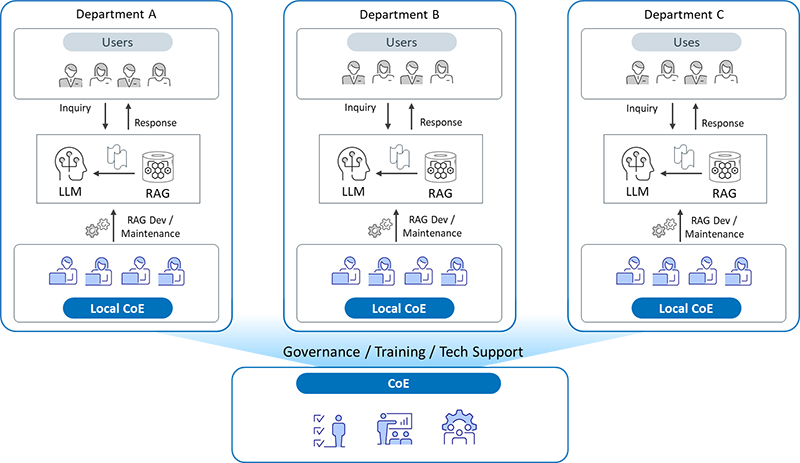
Figure 3: Democratizing RAG Development
3. What's Needed to Democratize RAG Development
To democratize RAG development, organizations should focus on three areas:
- Creating an environment for autonomous RAG development.
- Offering support for expanded generative AI usage.
- Providing governance for RAG development and operation.
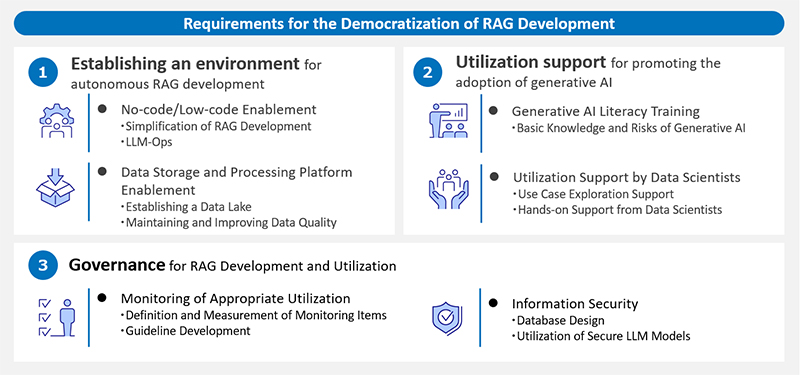
Figure 4: Key Elements Needed to Democratize RAG
For establishing an environment for autonomous RAG development, a no-code/low-code environment is essential because:
- Few departments have staff with coding skills.
- It streamlines the construction and tuning of vector databases (VDBs).
- It simplifies integration with internal systems.
- It provides a visual way to identify areas that need improvement.
The next step is to create a data lake to store and process reference data. This includes standardizing document formats and adding metadata to ensure data quality.
Equally important is education. To use generative AI responsibly, users must understand risks such as hallucinations and data leakage: how they occur, and how to mitigate them.
To ensure continued adoption, organizations must also provide support for expanding use cases and promoting internal uptake.
Governance requires the business to define usage guidelines and monitor compliance from the beginning. Key metrics to track this include cost, accuracy, hit rate, precision, and safety. Security measures - such as segregated databases and secure LLM environments - are also essential.
4. NTT DATA Services
At NTT DATA, we are expanding our support services and AI platforms to enable democratized RAG development. This includes running workshops to build AI literacy, helping departments identify areas with the potential for high ROI, and offering hands-on guidance from data scientists.
We also provide systems integration for data platforms, consult on data management, and design governance frameworks.
In addition, we support the use of DataRobot, an enterprise AI platform that streamlines RAG development and governance. DataRobot provides:
- A GUI that allows users to build and tune vector databases (VDBs).
- A playground environment where users can test LLMs and parameter combinations.
- Guardrails that block hallucinations, prompt injection, and PII leakage.
- APP templates that allow teams to build tools with minimal coding.
Playground Overview: https://docs.datarobot.com/en/docs/gen-ai/playground-tools/playground-overview.html
AI Apps Overview: https://www.datarobot.com/product/ai-apps/
These features allow departments to build RAG systems while enforcing governance effectively.
5. Conclusion
In this article, we have explained how organizations can apply RAG to business operations and what they must do to make it work.
Alone, generic LLMs will be of limited use. With RAG, LLMs gain access to internal data and generate more accurate, relevant responses, enabling broader adoption of generative AI across business functions.
NTT DATA envisions a future in which AI agents autonomously extract, organize, and execute tasks across entire workflows. Based on our "Smart AI Agent™"* concept, we are introducing new generative AI services to realize this vision.
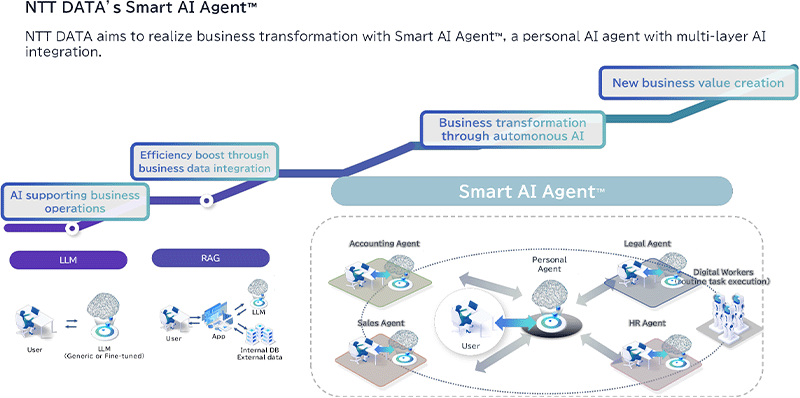
Diagram: Smart AI Agent™ Concept
If you want to apply generative AI in your organization and are considering the next steps, please reach out to us.
- * Smart AI Agent is trademark of NTT DATA Group Corporation in United States, European Union, United Kingdom and Japan.

Ryusuke Terada
Industry Sales Division, Technology Consulting Sector
Joined NTT DATA in 2018 as a mid-career hire. Since joining, engaged in supporting DX promotion primarily for clients in the financial and public sectors. Currently dedicated to advancing clients' AI and data utilization.

Kento Okada
Digital Success Solutions Division, Technology Consulting Sector
Engaged in data utilization consulting, including strategy formulation and execution support for AI adoption using AutoML. Currently promoting "Digital Success®" to realize business transformation for clients.

Kohei Okamoto
Generative AI Business Strategy Department
Since 2023, working as an AI Success Manager at DataRobot, engaged in AI utilization consulting for clients primarily in the manufacturing industry. Promoting broad AI adoption, including thematic support with generative AI.

Bo Zhao
Generative AI Business Strategy Department
As an AI Success Manager at DataRobot, responsible for AI utilization consulting primarily for clients in the manufacturing industry. Also engaged in business transformation leveraging generative AI.